数据库一体机简史:数据仓库一体机,因Netezza而得名
2003年,一个黑色的机柜悄悄运进了美国一家零售商的机房。几天后,那家公司的负责人打来电话,声音里带着难掩的激动:原本需要整整一夜才能跑完的分析报表,在这台机器上不到一小时就完成了——而且价格还不到原系统的一半。这台机器的制造者,是一家名不见经传的马萨诸塞州创业公司——Netezza。
如果说数据库一体机的历史是一部波澜壮阔的商业战争史,那么这场战争的主战场,在很长一段时间里,就叫做“数据仓库”。在这片江山上,Teradata曾是无可争议的王者,而Netezza的出现则改变了竞争格局,它所掀起的波澜,将在此后十年间彻底重塑数据仓库市场。
01.
聚数成仓:数据仓库概念的诞生
在深入讲述Netezza之前,我们必须先回溯数据仓库这一概念的诞生,因为正是这个概念的出现,定义了整个战场。
1988年,IBM爱尔兰研究中心的两位研究员——巴里·德夫林(Barry Devlin)和保罗·墨菲(Paul Murphy)——发表了一篇题为"An Architecture for a Business and Information System"(商业与信息系统的体系架构)的论文,刊载于《IBM系统期刊》(IBM Systems Journal)。在这篇论文中,他们首次正式提出了“商业数据仓库”(Business Data Warehouse,简称BDW)的概念,将其定义为用于商业报告的包含所有信息的单一逻辑仓库。
然而,这个概念在IBM内部几乎石沉大海——毕竟,那是一个主机和专有软件大行其道的年代,IBM的营收来自销售服务器和DB2、IMS数据库,而不是来自帮助用户打通数据孤岛。德夫林和墨菲的论文发表时,IBM的几位高管只是礼貌地点了点头,随即将其束之高阁。多年后,德夫林在回忆这段往事时不无苦涩地说:“我们早就把答案写出来了,只是没人想看。”IBM对数据仓库这一新生概念的漠视,恰恰为日后大量创业公司打开了机会之窗。

这本书的出版,标志着数据仓库正式从学术概念走向工程实践。比尔·恩门也因此获得了“数据仓库之父”的称号。然而,学术界的故事并未就此平静。就在恩门的书出版后不久,另一位数据仓库大师拉尔夫·金博尔(Ralph Kimball)于1996年出版了《数据仓库工具书》,提出了截然不同的“维度建模”(Dimensional Modeling)方法论。恩门主张从企业全局出发、自上而下地构建高度规范化的企业数据仓库;金博尔则主张以部门需求为核心、自下而上地构建数据集市(Data Mart)。两派论战持续近三十年,在业界引发无数争论,至今没有定论——但这场争论本身,反而让“数据仓库”这个概念深入人心。随着数据仓库的概念成型,Teradata的历史价值才真正得以彰显。
02.
因仓而起:Netezza为数仓一体机正名
事实上,Teradata在1979年创立时,数据仓库这个词还不存在。但其创始人杰克·谢默(Jack Shemer)和菲利普·尼奇斯(Philip Neches)在加州理工学院附近的一间小办公室里构想的系统,天然契合了日后数据仓库对大规模并行分析的需求。Teradata首台样机DBC/1012于1984年以百万美元高价交付给美国富国银行——用户愿意买单,因为它能做到其他任何系统都做不到的事:同时处理来自数百个终端的复杂分析查询,而不崩溃。到1990年代,Teradata已成为数据仓库领域无可争议的霸主,为沃尔玛、美国银行、联邦快递等巨头构建了动辄数十乃至数百TB规模的系统。然而,绝对的领先地位,有时也是骄傲的温床。


这是一对教科书式的互补搭档:欣肖沉默寡言,脑子里装的全是硬件逻辑和磁盘I/O;萨克塞纳能说会道,开口必谈市场痛点和投资人关系。欣肖可以在白板上画出整套FPGA数据过滤管道,但让他去见投资人会让双方都如坐针毡;萨克塞纳则能在风险投资人面前把一块芯片讲成一场革命,却对电路原理一窍不通。公司A轮融资从Charles River Ventures和Matrix Partners拿到了800万美元,在马萨诸塞州弗雷明汉一个普通工业园区里磕磕绊绊地造出原型机。萨克塞纳随后拉来了前Sun Microsystems首席执行官埃德·赞德2(Ed Zander)——他在Data General时代的旧友——加入董事会,此举立刻让整个行业重新审视这家名不见经传的创业公司。除了赞德,萨克塞纳还利用他在波士顿科技圈的人脉,组建了一个阵容强大的董事会。这种“老友记”式的创业模式是Netezza早期能够迅速获得大客户(如沃尔玛、亚马逊等早期测试客户)信任的关键原因。
1 乌尔都语是巴基斯坦的国语,也是印度的23种官方语言之一,属于印欧语系印度-伊朗语族印度语支。乌尔都一词源自波斯语,原意为“军营”或“营地”。
2 埃德·赞德(Ed Zander)是硅谷和科技界的“摇滚明星”级高管。他曾任Sun Microsystems的总裁兼首席运营官(COO),并在2004年至2008年期间担任摩托罗拉(Motorola)的董事长兼CEO。Data General是70-80年代波士顿“128号公路”科技走廊的传奇公司(曾是DEC的最大竞争对手)。吉特当时是Data General的软件开发副总裁。埃德·赞德当时也在Data General担任营销方面的高级职位。正是这段在同一家公司的“战友”情谊,为后来的联手埋下了伏笔。
在2000年前后,互联网泡沫正在破碎,但数据却以前所未有的速度膨胀。电商记录每一次点击,电信公司记录每一通电话,超市扫描每一件商品。各家企业拥有了前所未有的数据,却发现自己站在数据的汪洋中,望洋兴叹——分析报表要跑一整夜,等结果出来,商机早已错过。“数据爆炸”但“分析极慢”,成了那个时代所有首席信息官最头疼的难题。常规的数据流处理逻辑是,从硬盘读取大量数据,通过总线传输到CPU,在内存中进行复杂的运算。在这个流程中,硬盘读取速度慢,总线传输带宽窄,这就成为了著名的“I/O瓶颈”。欣肖认为,不应该把数据搬运到计算单元(CPU),而应该让计算直接发生在数据存放的地方。为此,他们利用了FPGA3(Field-Programmable Gate Array,现场可编程门阵列,如图4所示)芯片,在数据从硬盘读出的那一瞬间,就直接在硬件层过滤掉不需要的信息。
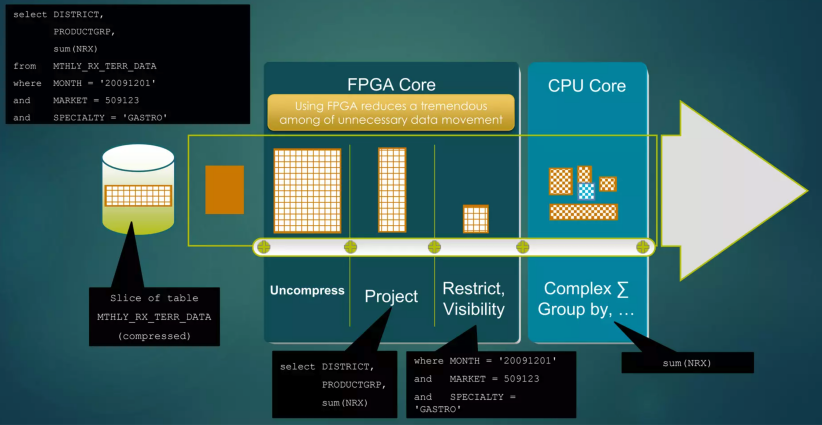
图4 Netezza的FPGA工作原理
3 FPGA即现场可编程门阵列,是一种可在出厂后由用户编程配置的集成电路。与通用CPU不同,FPGA可通过硬件逻辑实现特定算法,在执行特定任务时具有极高的并行度和能效比。Netezza将FPGA用于数据过滤——在数据从磁盘读出的瞬间,FPGA以硬件速度执行行级过滤,只将匹配条件的数据传递给CPU处理。这种“近数据计算”架构大幅减少了数据搬运,有效缓解了I/O瓶颈,是Netezza性能优势的核心技术。
Netezza的诞生是数据仓库(Data Warehousing)历史上的一场“革命”。它并没有走当时主流的“软件优化”路线,而是通过软硬件一体化的思路,硬生生地在被Oracle和Teradata垄断的市场中撕开了一道口子。
Netezza的灵感来源于Britton-Lee。Netezza用的FPGA芯片,本质上就是20年后更先进、更便宜的“Britton-Lee硬件加速器”,所以Netezza被认为是IDM(Intelligent Database Machine)的现代复兴。更值得一提的是,Britton-Lee“不能独立计算”的基因也被Netezza继承并改良了,Netezza内部专门设了一个“Host”服务器(前端机,如图5所示)。后端的FPGA和S-Blades依然只负责“暴力扫描数据”,它们还是没法处理复杂的财务逻辑或网页展示。Netezza的前端机就像是当年的“主机”,负责接待用户并解析SQL,然后再把指令发给后端的“数据库机器”。Netezza的核心架构被称为AMPP(Asymmetric Massively Parallel Processing,非对称大规模并行处理),分为两个层次:
-
前端层(Host服务器):运行Linux SMP系统的主机,负责接收SQL查询、编译成执行计划、分发任务,以及最终汇总来自后端的结果。Host服务器本身不参与数据扫描,它是整个系统的“大脑”和“调度员”。这种设计让人想起Britton-Lee的IDM系统——同样有一台专门的“主机”处理复杂的业务逻辑和用户交互,后端的加速器只负责数据处理。Netezza内部将这台Host称为“前端机”,它的作用是当年大型机(主机)角色的精神传承:接待用户、解析SQL,再把指令发给后端的“数据库机器”。
-
后端层(S-Blade,片段处理刀片):每一块S-Blade(即图5中的SPU)是一个完整的数据处理单元,包含一个多核Intel PowerPC CPU、专有的FPGA芯片,以及若干硬盘。FPGA在数据从硬盘读出的瞬间执行过滤,将不需要的数据直接丢弃,CPU只处理被FPGA放行的少量数据。数十乃至数百块S-Blade并行工作,数据被均匀分布在所有S-Blade上。2009年,Netezza从PowerPC转向Intel CPU,并采用了IBM刀片服务器平台,性能进一步提升。
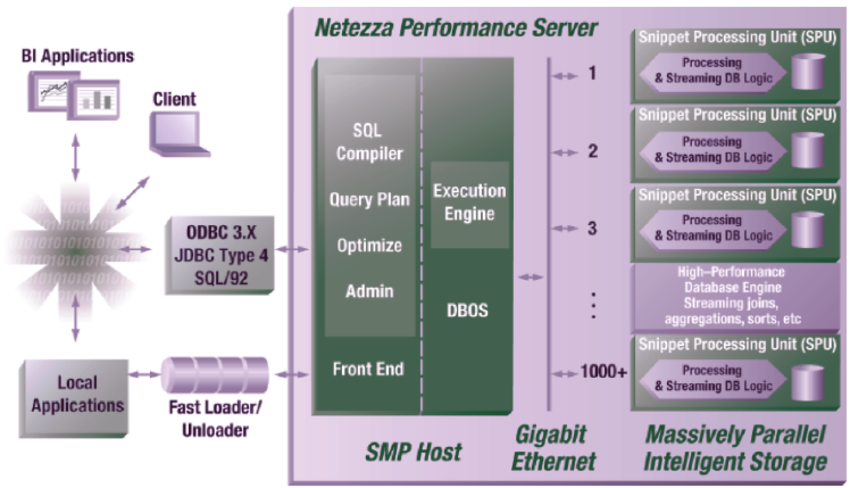
图5 Netezza一体机架构图
Netezza最经典的机型叫做TwinFin4,外观呈现为一个黑色的服务器机柜,内部密布着S-Blade和散热系统,机柜背面整齐排列着数以百计的电缆接口,有一种工业美感。据早期工程师回忆,TwinFin在满载工作时会发出一种稳定的低频嗡嗡声,工程师们亲切地称之为“数据引擎的心跳”,成为Netezza品牌的标志性记忆。整个系统的查询处理能力与S-Blade的数量完全线性相关——添加更多的S-Blade,性能就等比例提升,没有任何单点瓶颈,这种优雅的线性扩展性在当时的市场上极为罕见。
4 TwinFin是Netezza最经典的一体机机型。TwinFin的名称寓意“双鳍”,象征其前后端分离的AMPP架构。该机型的查询处理能力与S-Blade数量呈线性关系,添加更多S-Blade即可等比例提升性能,没有任何单点瓶颈。
2002年秋,Netezza推出了首款正式商用产品NPS 8000系列,起步价62.2万美元。Netezza当时的营销口号是“比竞争对手便宜10倍”。当时要处理同等规模的数据,购买Teradata的硬件或者在高端服务器上运行Oracle的总成本通常在500万至1000万美元之间。2003年,改进版Performance Server正式发售,其后端的数据库是基于PostgreSQL 7.2改进的,配合Netezza的AMPP硬件架构,综合性能令业界震惊。当时它的处理速度比传统商业数据库快10到100倍。
早期客户的测试结果令人震惊:Epsilon公司(一家营销数据分析公司)在测试后报告,Netezza的查询速度比其之前使用的IBM系统快20倍,而成本仅为IBM系统的一半;TJX公司(The TJX Companies,美国最大的折扣零售商之一)表示,原本需要整整一夜才能跑完的分析作业,在Netezza上不到一小时就能完成。这些数字对Teradata的用户来说,简直像是一个来自未来的故事。
2003年,Netezza在发布首款产品的同时,还做了一件意义深远的事:他们在当年的VLDB国际会议上发表了一篇工业报告,首次在学术界和工业界的双重舞台上正式提出了"Data Warehouse Appliance"(数据仓库一体机)这一概念,并将其定义为:“将存储、处理和数据库管理系统集成在单一系统中的闭环设备(A closed system integrating storage, processing, and DBMS in a single unit)”。
这是一个历史性的命名时刻。Netezza用这篇论文,为整个行业树起了一面旗帜。从此,“数据仓库一体机”成为一个真正意义上的产品品类。Netezza虽然是挑战者,但它同时也是这个品类的命名者和定义者——这在商业竞争史上是极为罕见的成就。
2004年,Netezza已拥有15家客户,交付了35套系统,并在年底实现盈利。公司的目标市场规模,2003年仅数据仓库系统一项的全球支出就达到155亿美元。一时间,大量正在因为Teradata的高价和响应迟缓而苦恼的企业,将目光转向了这家来自马萨诸塞州的小公司。
03.
无需调优:Netezza靠简易颠覆传统
Netezza的崛起,让Teradata坐不住了。Teradata首席技术官斯蒂芬·布罗布斯特(Stephen Brobst)——前MIT教授、数据仓库领域公认的权威——在2003年前后公开开炮,嘲讽Netezza不过是把已倒闭的超算公司Thinking Machines和Kendall Square Research的旧人马和旧想法重新拼凑了一遍,并断言这种设计根本不适合真正的决策支持场景。对此,萨克塞纳只淡淡回了一句:“他根本没理解我们在做什么。”市场用真金白银给出了裁决。Netezza通过一体机的“开箱即用”模式,彻底打破了Teradata的牢固壁垒。Netezza的成功,从技术层面来说固然令人叹服,但更深层的原因,是它将一种全新的商业哲学带入了数据仓库市场——"No Tuning"(无需调优)。"No Tuning"这两个词,对于那个时代所有被数据库调优折磨的DBA来说,简直像是一道治愈心灵的宣言。
在传统的Oracle或Teradata数据库中,“调优”是一门深奥的黑魔法。一个优秀的DBA需要:为高频查询建立正确的索引,否则全表扫描会让系统慢如蜗牛;定期收集统计信息,以便优化器生成正确的执行计划;精心设计分区方案,将热数据和冷数据分开存储;监控查询计划,识别并消除“笛卡尔积”等毁灭性的查询错误;以及在系统扩容时处理复杂的数据重分布5(Re-hashing)操作……
5 数据重分布(Re-hashing)是分布式数据库在扩容或数据分布不均时进行的重新数据分布操作。在MPP架构中,数据通常按哈希值分布到各节点,当增加新节点或数据倾斜严重时,需要重新计算哈希值并将数据迁移到正确位置。Re-hashing是分布式数据库运维的复杂操作,可能导致长时间停机或性能抖动。Netezza通过均匀分布策略和线性扩展架构避免了Re-hashing需求,是其"No Tuning"理念的重要体现。
Netezza的一体机理念,让用户可以像家电一样开箱即用,不需要像Oracle那样聘请昂贵的数据库管理员(DBA)进行复杂的调优,也不需要像Teradata那样进行复杂的部署和调试。Netezza通过AMPP架构的设计哲学彻底回避了这些问题:FPGA的暴力扫描架构意味着不需要索引,数据直接推入就能查询;均匀分布的并行架构意味着不需要精心设计分区;线性扩展的S-Blade意味着扩容不需要Re-hashing。用户只需要把数据载入Netezza,然后提交SQL,就能得到结果——和传统数据库相比,这简直就是两种技术范式的碰撞。
Netezza的"No Tuning"哲学,带来了一个意料之外的市场效果:它的用户不再主要是技术极客,而是业务分析师。在Netezza之前,能够操作数据仓库系统的人,必须是经验丰富的数据库工程师。但Netezza的简单性和快速性,让那些只会写SELECT语句的业务人员也能直接上手。相较而言,Teradata的门槛非常之高,它像一辆赛车,需要专业技师(高级DBA)长期维护、调优、设计索引。
这一变化的商业意义极为深远。当“数据分析”从工程师的专属领地变成业务团队的日常工具时,数据分析的需求量就呈现出指数级增长——更多的分析师提出更多的问题,更多的问题催生更多的查询,更多的查询驱动更多的系统购买。Netezza通过降低使用门槛,创造了属于自己的需求。这一逻辑,在后来的Tableau、Power BI等商业智能工具中被反复验证。Netezza是最早将这一逻辑应用于数据仓库基础设施层的公司。
在商业层面,Netezza的发展轨迹同样令人印象深刻:2002年1月完成Battery Ventures领投的2500万美元B轮融资;2003年7月完成红杉资本(Sequoia Capital)领投的2000万美元C轮融资——红杉是Google和Apple的早期投资人,这次背书让整个行业对Netezza刮目相看。
2005年,福斯特·欣肖离开Netezza,创立了一家名为Dataupia的新公司,专注于更大规模的数据存档解决方案。他的离开,标志着Netezza从技术驱动向商业驱动的转型完成。2007年7月,Netezza以股票代码"NZ"在纽约证券交易所成功上市,完成了吉特·萨克塞纳这位连续创业者人生中的又一次资本市场征程。2008年,联合创始人吉特·萨克塞纳宣布退休,将CEO一职交给了2006年加入的吉姆·鲍姆(Jim Baum)。
故事并未在此落幕。2010年9月20日,IBM宣布以每股27美元、总价约17亿美元的现金全面收购Netezza——距离福斯特·欣肖在特拉华州注册那家小公司,恰好整整十年。一个人在工业园区里画出的电路图,最终以17亿美元的价格,嵌进了世界上最大的科技公司的版图。
04.
zData:中国市场的"No Tuning"传承者
在Netezza所代表的“开箱即用”(Appliance)哲学在西方市场大获成功的同时,中国的数据库市场正在经历一场深刻的变革。2010年代,中国企业的数据量和数据分析需求急速增长,Oracle、IBM、Teradata的传统产品虽然强大,但高昂的价格和对高端DBA的依赖,对于大量中型企业来说仍是难以逾越的门槛。就在这一背景下,云和恩墨走上了与Netezza相似的历史舞台。
云和恩墨成立于2011年,核心技术团队包括中国数据库技术圈最早的一批Oracle ACE总监(峰值期间有6位)。云和恩墨的技术专家在长达20余年的时间里为中国各行业客户处理Oracle数据库的疑难杂症,深知Oracle“功能强大但运维复杂、价格昂贵”的双重特性。在这个历史窗口期,云和恩墨开始了一条独特的zData一体机产品创新之路。
zData的设计思路与Netezza有异曲同工之妙,但是更进一步。No Tuning不是真正的“不优化”,而是在出厂前深度优化,将复杂消弭于用户应用之前,自己极繁、而用户极简。云和恩墨的企业基因是数据库优化,所以zData不仅能够将数据库所需的计算、存储、网络、监控管理等组件预先集成并优化,更能够针对不同品类的数据库设计最佳实践,并实现自动化部署。这样,用户在zData上线后,不需要懂存储架构、不需要进行复杂的数据库规划,接通电源、完成简单配置部署,即可将现有数据库迁移上去——“开箱即用”,这正是Netezza的核心哲学在中国场景下的精准复刻。云和恩墨的一站式数据库环境构建方式,为用户带来了极致简化的应用体验(如图6所示)。
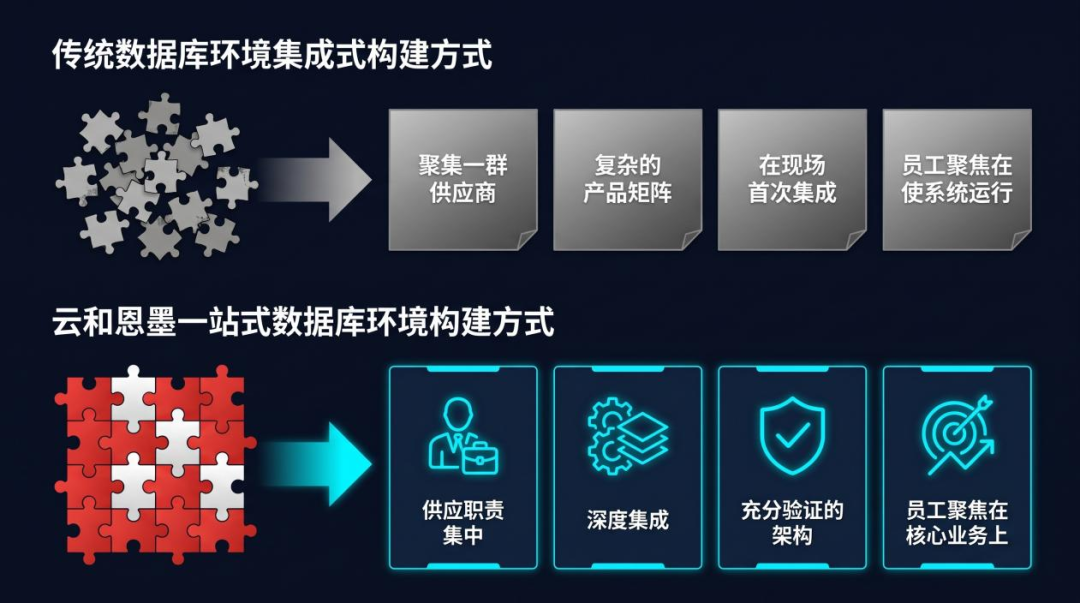
图6 云和恩墨一站式数据库环境构建方式
与Netezza构建专用硬件不同的是,云和恩墨构建的是通用分布式存储软件。这是一条极具挑战的道路。分布式存储是计算机科学中最复杂的领域之一,涉及分布式一致性、数据冗余、故障自愈、性能优化等数十个子领域。云和恩墨的工程团队选择了一条有别于Ceph通用分布式文件系统的路线:专门针对数据库I/O模式进行优化,开发了zStorage——一套去中心化的分布式块存储软件,专门为数据库的读写特性量身定制。zStorage采用去中心化架构,I/O通过哈希直接寻址,无需查询元数据,减少交互环节,大幅降低时延;搭载高速InfiniBand网络(带宽达200Gb/s);使用NVMe闪存SSD,释放闪存潜能。
中国移动某省公司的实践是对这套架构最好的验证之一。2018年,该省移动的多套系统中就存在数据量快速增加,性能衰减严重,同时存储无法扩展等问题,其中性能问题尤以I/O慢最为突出。面对数百TB的实时计费系统、上百TB的数据仓库带来的巨量I/O压力,zData采用了6台高端x86服务器作为支撑三套RAC的计算服务器,配合插入多块高I/O闪存卡的15节点存储服务器,以裸容量1.2PB、三副本后实际可用存储空间400TB,构成具备高计算能力、千万级高IOPS能力、百GB级IO吞吐能力和高可用能力的分布式架构(如图7所示),全面支撑具有巨量IOPS需求的高并发交易,以及海量数据吞吐需求的批处理、数据统计、报表等业务的高效运行。2019年6月zData上线后,核心业务的运行速度明显加快——系统整体性能提升超过5倍,在真实生产环境中得到了充分验证。
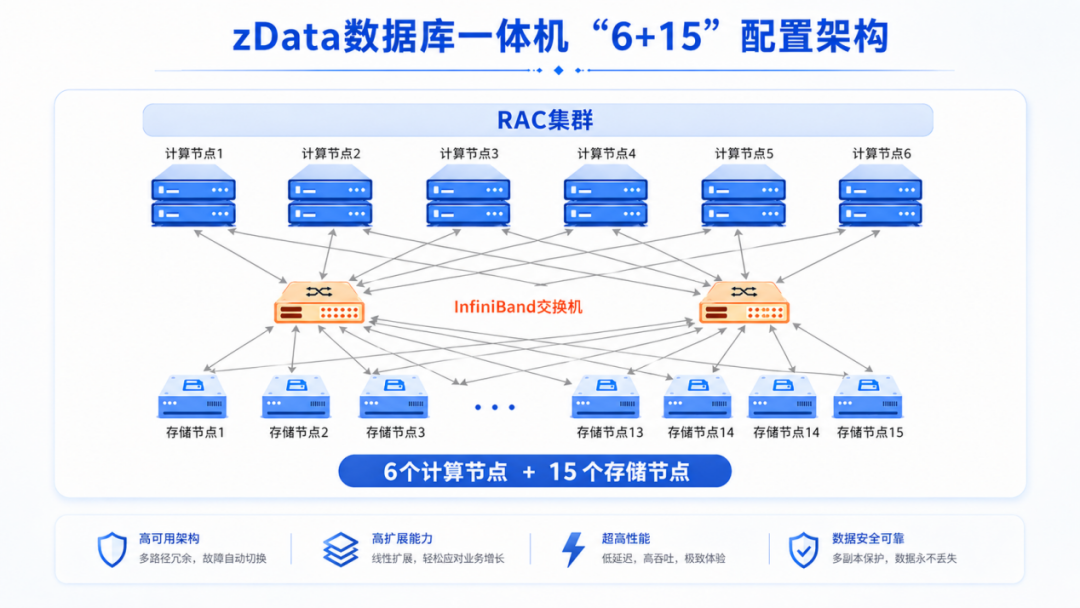
图7 zData在某省移动的“6计算节点+15存储节点”配置架构
05.
洞察入微:技术的商业化路径
回顾Netezza的历史,其成功的核心是在技术创新与市场洞察的交汇处找到了一个切入点——在I/O瓶颈最为严重、DBA资源最为稀缺的时代,提供了一个“硬件+软件+服务”深度集成的闭环解决方案。
云和恩墨的zData,同样是在中国数据库市场的特殊矛盾中找到了自己的切入点:在国产化替代的政策背景下,在Oracle等外资数据库的高成本与高复杂度面前,提供一个“通用、易用、可扩展”的数据库承载平台,让企业不必更换数据库应用,只需更换底层基础设施,即可获得成倍的性能提升和成本节约。
更深远的意义在于:zData是数据库一体机这一产品品类在“多元数据库时代”的进化形态。Netezza只支持一种数据库(基于PostgreSQL的Netezza数据库);Oracle Exadata主要为Oracle数据库服务;而zData打破了“一体机=单一数据库”的桎梏,真正实现了让任意数据库在同一套优化硬件上以最优性能运行的愿景——这是过去任何一款数据仓库一体机都未曾实现的目标。