SQL问题分析之解读执行计划-GaussDB T 性能调优大全
墨天轮原文链接:https://www.modb.pro/db/22223
解读执行计划
查看执行计划
GaussDB T默认开启RBO,开启和关闭CBO需要执行SQL语句。
--开启CBO
ALTER SYSTEM SET CBO = ON;
--关闭CBO
ALTER SYSTEM SET CBO = OFF;
使用explain (plan for) + SQL语句打印执行计划
对于上述执行计划的每一列的含义说明:
● Id:行号。
● Description:执行计划具体信息包括:表的扫描方式,索引的选择,多表的连接方式,过滤条件等。
● Owner:表所在的用户。
● Name:表或者索引的名称。
● Rows:CBO预估的行数。
● Cost:CBO用于选择执行计划的代价。
对于执行计划下方显示的谓词信息(Predicate Information):
通过执行计划的行号(Id)对应
● access:两表之间的关联条件
● fiÃìr:表的过滤条件
与表相关的执行计划
● 全表扫描(table access full)
在GaussDB T中使用TABLE ACCESS FULL表示对cbo_ef_data_1w_s走全表扫描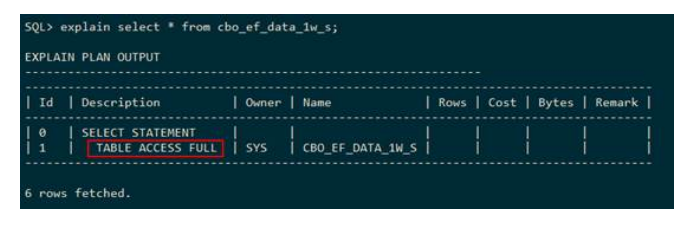
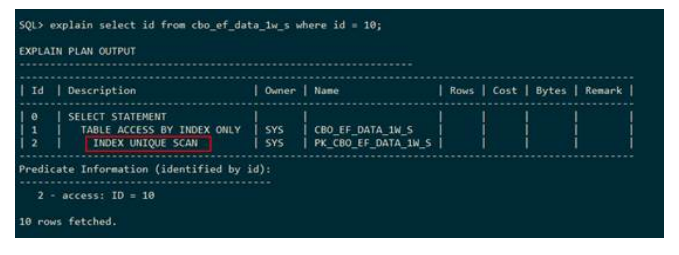
● 仅通过索引的表扫描(table access by index only)
GaussDB T在执行计划中使用TABLE ACCESS BY INDEX ONLY表示对表cbo_ef_data_1w_s仅走索引扫描
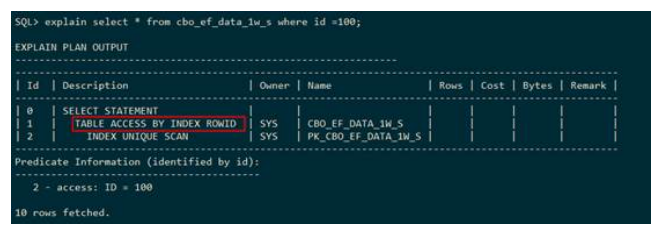
● 通过rowid回表的表扫描方式(table access by index rowid)
GaussDB T在执行计划中使用TABLE ACCESS BY INDEX ROWID表示对表 cbo_ef_data_1w_s走ROWID扫描
与索引相关的扫描方式
● 索引唯一扫描(index unique scan)
GaussDB T在执行计划中使用INDEX UNIQUE SCAN表示对表cbo_ef_data_1w_s 中的索引pk_cbo_ef_data_1w_s走索引唯一扫描。
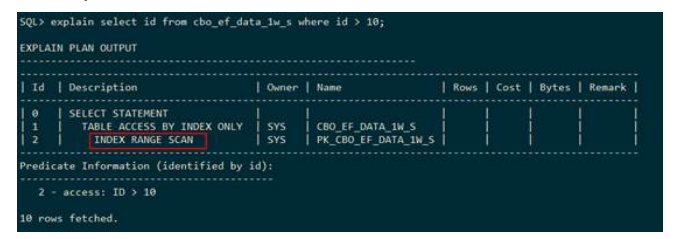
● 索引范围扫描(index range scan)
GaussDB T在执行计划中使用INDEX RANGE SCAN表示对表cbo_ef_data_1w_s中的索引pk_cbo_ef_data_1w_s走索引范围扫描。
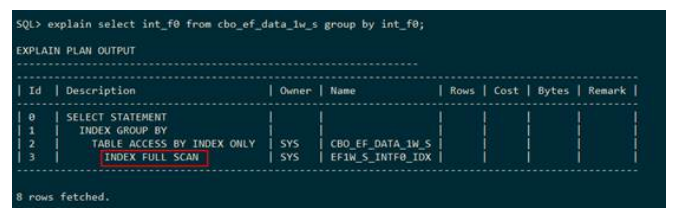
● 索引全扫描(index full scan)
GaussDB T在执行计划中使用INDEX FULL SCAN表示对表cbo_ef_data_1w_s中的索引ef1w_s_intf0_idx走索引全扫描。
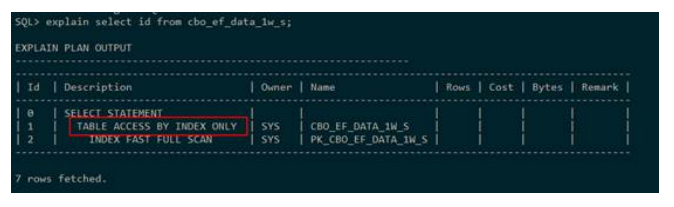
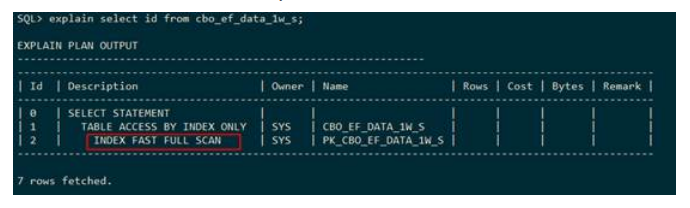
● 索引快速全扫描(index fast full scan)
GaussDB T在执行计划中使用INDEX FAST FULL SCAN表示对表
cbo_ef_data_1w_s中的索引pk_cbo_ef_data_1w_s走索引快速全扫描
● 分布式扫描(remote scan)
分布式执行计划中,REMOTE SCAN表示将SQL语句下推到DN上执行。
explain select * from t1;
EXPLAIN PLAN OUTPUT
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Description | Owner | Name | Rows | Cost | Bytes | Remark |
---------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | | |
| 1 | REMOTE SCAN | | | | | | PUSHDOWN SQL: SELECT AA,BB FROM
SHARDING_REGRESS.T1 |
---------------------------------------------------------------------------------------------------------------------
与表连接的执行计划
● NESTED LOOPS
– NESTED LOOPS(嵌套循环连接)
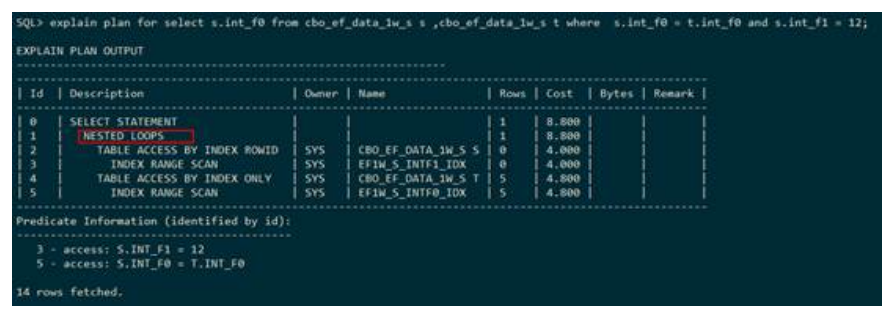
下列执行计划显示,表S和表T走的是嵌套循环连接,连接条件为
s.int_f0=t.int_f0,这里嵌套循环连接的驱动表是表S,嵌套循环连接的在执行
计划中使用NESTED LOOPS表示。
– NESTED LOOPS OUTER(嵌套循环外连接)
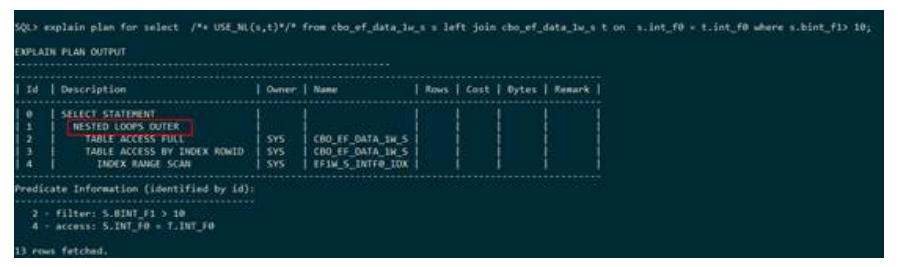
下列执行计划显示,表S和表T走的是嵌套循环外连接,连接条件为
s.int_f0=t.int_f0,这里嵌套循环连接的驱动表是表S,外连接在执行计划中使用OUTER
表示,嵌套循环外连接的在执行计划中使用NESTED LOOPSOUTER表示。
– NESTED LOOPS FULL(嵌套循环全连接)
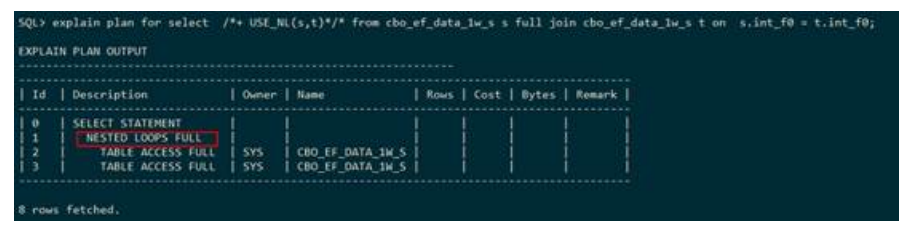
上述执行计划显示,表S和表T走的是嵌套循环全连接,连接条件为
s.int_f0=t.int_f0,这里嵌套循环全连接的驱动表是表S,全连接在执行计划中使用FULL
表示,嵌套循环全连接的在执行计划中使用NESTED LOOPS FULL表示。
● HASH JOIN(哈希连接)
哈希连接在执行计划中用HASH JOIN表示,并且后面的(L OR R)表示左表还是右表建立
HASH表。
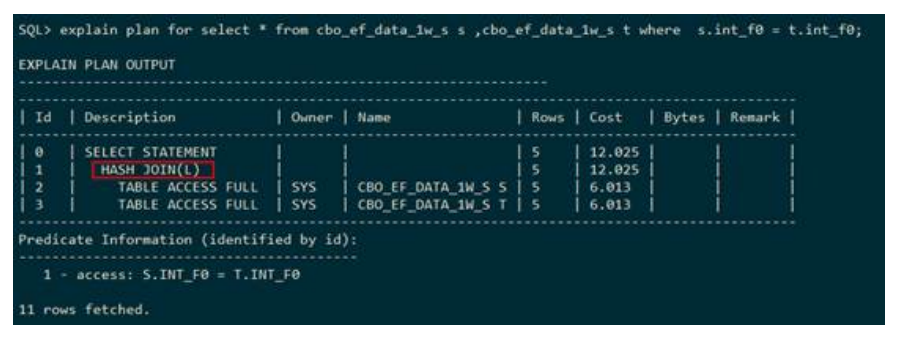
– 左表建立HASH
下列执行计划显示,表S和表T走的是哈希连接,并且建立哈希表的是表S,连接的条件是
s.int_f0=t.int_f0。
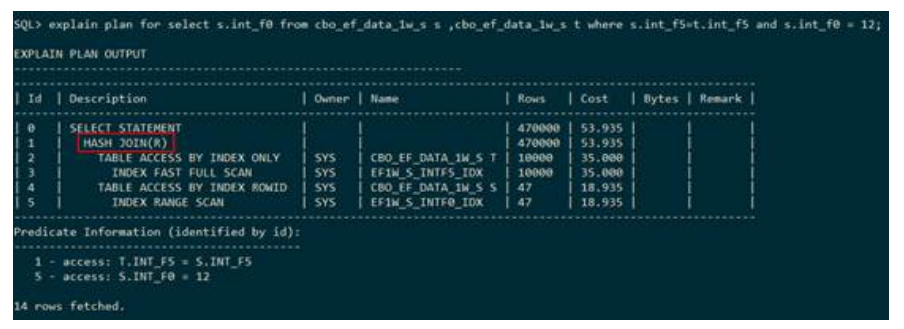
– 右表建立HASH
下列执行计划显示,表S和表T走的是哈希连接,并且建立哈希表的是表S,连接的条件是
s.int_f5 =t.int_f5。
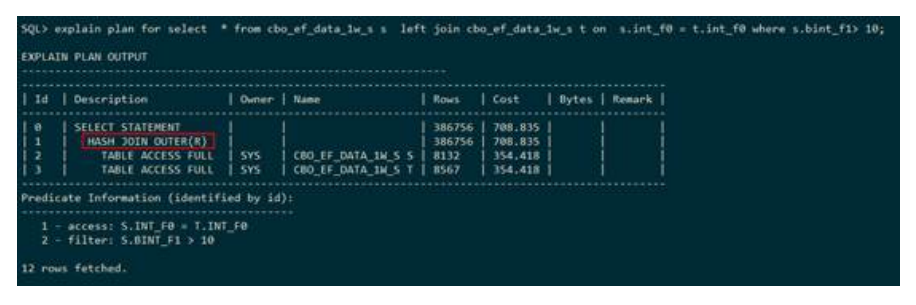
– HASH JOIN OUTER(哈希外连接)
下列执行计划显示,表S和表T走的是哈希外连接,并且建立哈希表的是表T,连接的条件是
s.int_f0 =t.int_f0。哈希外连接在执行计划中用HASH JOIN OUTER表示,并且后面的
(L OR R)表示左表还是右表建立hash表。
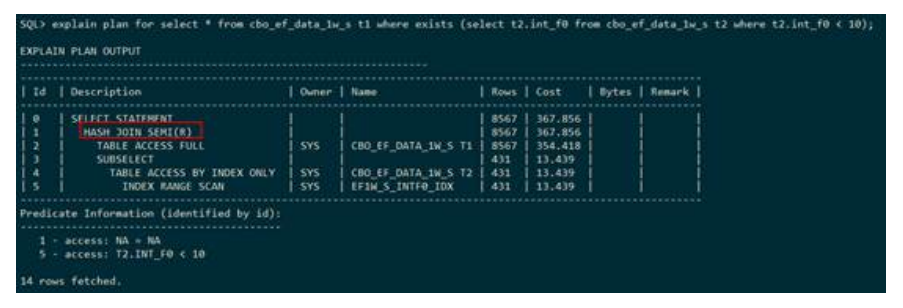
– HASH JOIN SIMI(哈希半连接)
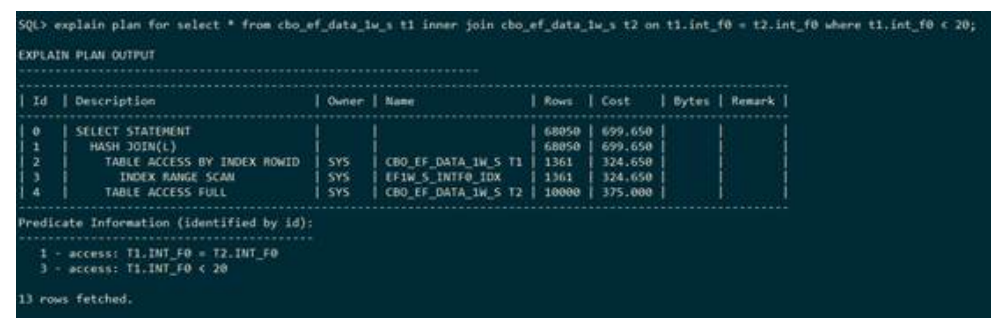
下列执行计划显示,表t1和表t2走的是哈希半连接,并且建立哈希表的是表t2,连接的条件是t1.int_f0 =t2.int_f0。半连接在执行计划中使用SIMI表示,哈希半连接在执行计划中用HASH JOIN SIMI表示,并且后面的(L OR R)表示左表还是右表建立hash表。
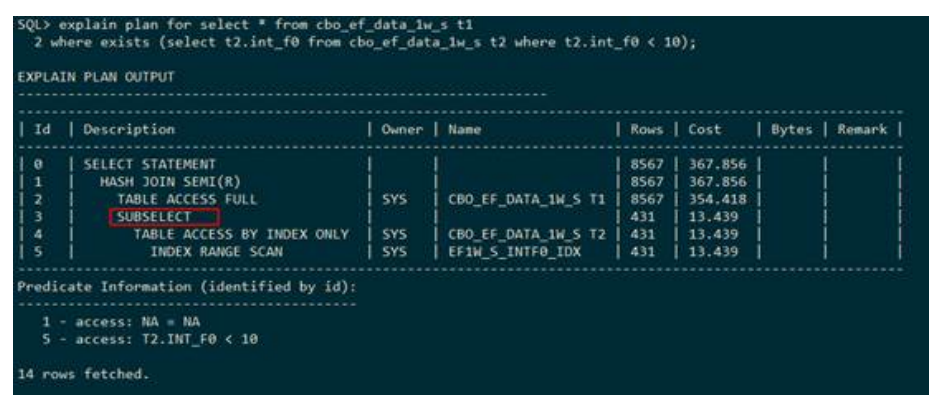
– HASH JOIN ANTI(哈希反连接)
下列执行计划显示,表t1和表t2走的是哈希反连接,并且建立哈希表的是表t2,连接的条件是t1.int_f0 =int_f0。反连接在执行计划中使用ANTI表示,哈希反连接在执行计划中使用HASH JOIN ANTI表示,并且后面的(L OR R)表示左表还是右表建立hash表。
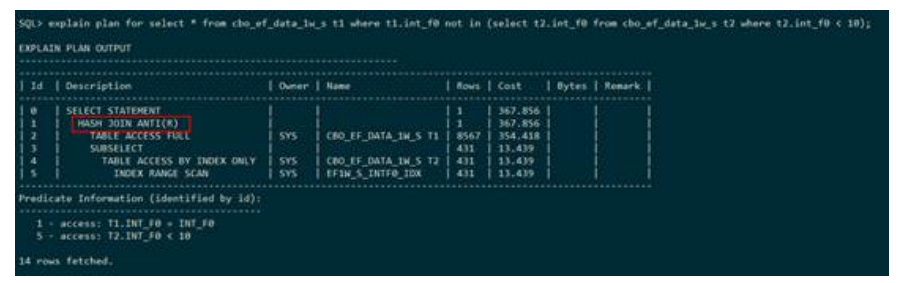
– HASH JOIN FULL(哈希全连接)
下列执行计划显示,表s和表t走的是哈希全连接,并且建立哈希表的是表s,连接的条件是s.int_f0 =t.int_f0。全连接在执行计划中使用FULL表示,哈希全连接在执行计划中使用HASH JOIN FULL表示,并且后面的(L OR R)表示左表还是右表建立hash表。
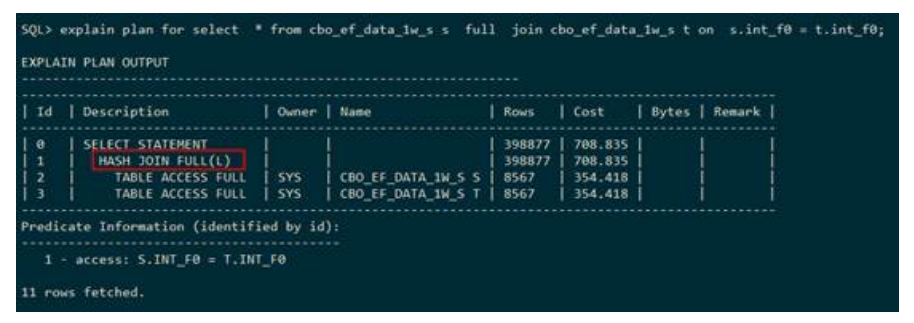
● MERGE JOIN(排序合并连接)
下列执行计划显示,表S和表T走的是排序合并连接,连接条件为t1.a > t2.a,排序
合并连接的关键字是MERGE JOIN。
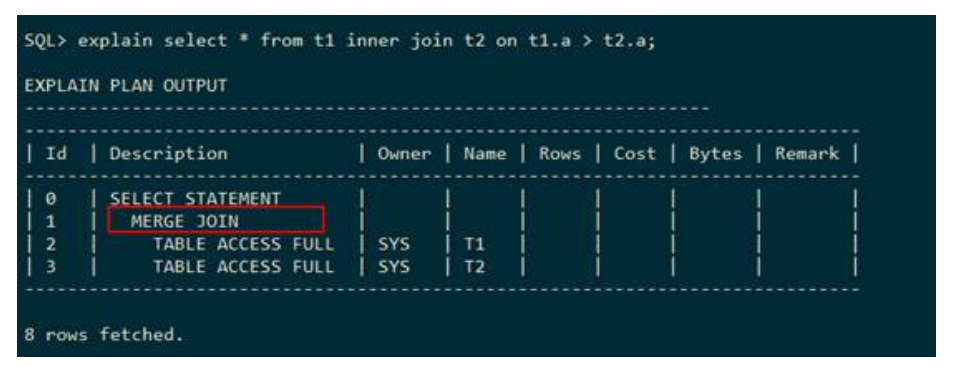
其他常见的执行计划
● SUBSELECT(子查询)
下列执行计划显示,表t3在一个子查询里面,表t1和这个子查询走哈希半连接,这个子查询作为一个整体来执行。执行计划中使用SUBSELECT表示子查询。
● VIEW(视图)
根据能否直接处理视图中的基础表分为两种情况:
– 能够直接处理视图中的基础表,此时执行计划中可能不会显示关键字VIEW。
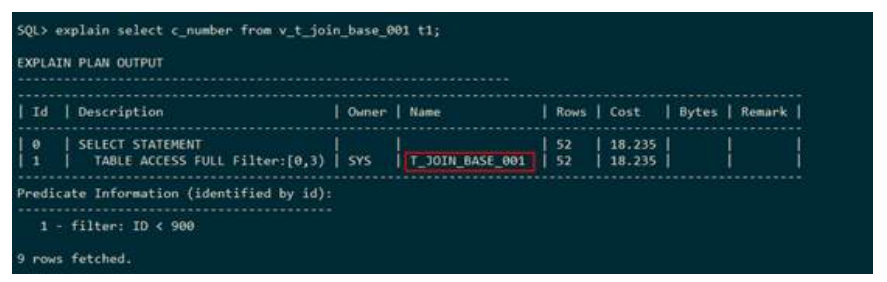
– 不能直接处理视图,此时将视图看做一个整体单独执行,此时在执行计划中就会显示关键字VIEW。
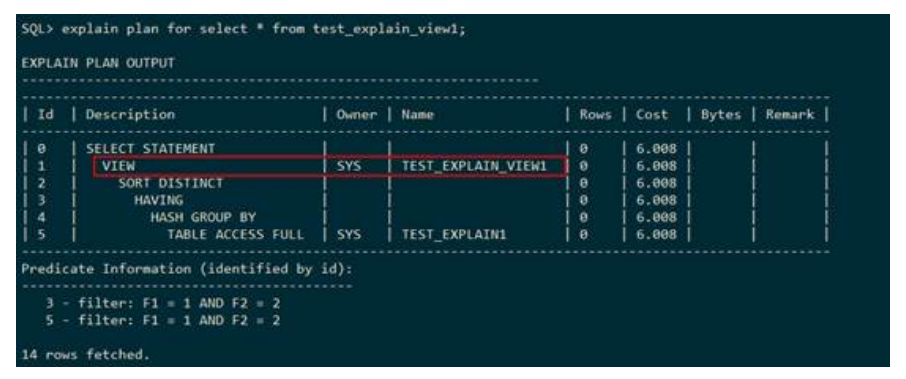
● FILTER
下列执行计划表示:首先fiÃìr会得到它下层的结果集,之后根据过滤条件去除不满足条件的数据,最终得到一个返回上层的结果集。
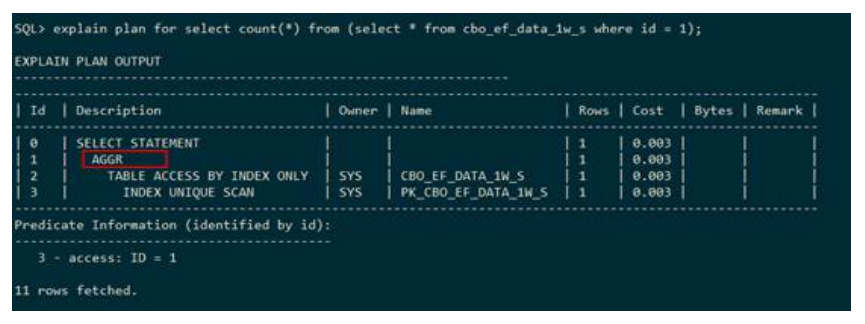
● 分组
– AGGR
下列执行计划表示:首先求出cbo_ef_data_1w_s满足条件的记录,之后对这些记录进行聚集函数求值。执行计划中使用AGGR表示将整个结果集作为一组。
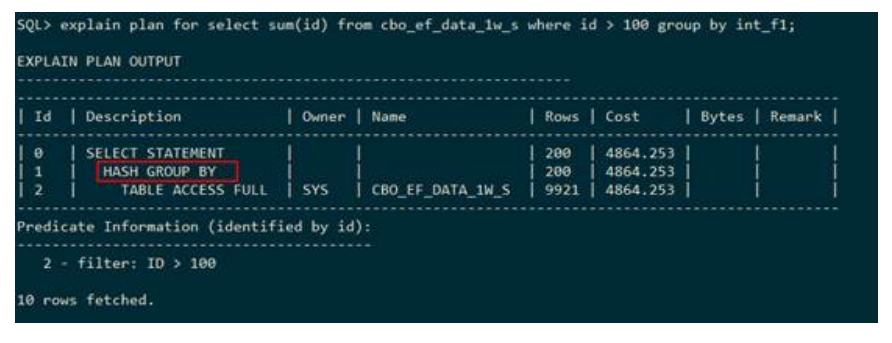
– HASH GROUP BY(哈希分组)
上述执行计划表示:通过使用建立hash表的方式进行分组,之后求聚集函数sum的值。执行计划使用HASH GROUP BY表示进行哈希分组
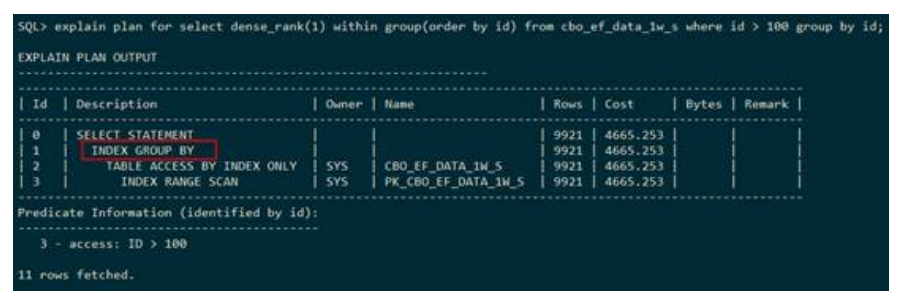
– INDEX GROUP BY(索引分组)
上述执行计划表示:通过使用索引的方式进行分组,之后求聚集函数sum的值。执行计划使用INDEX GROUP BY表示进行索引分组。
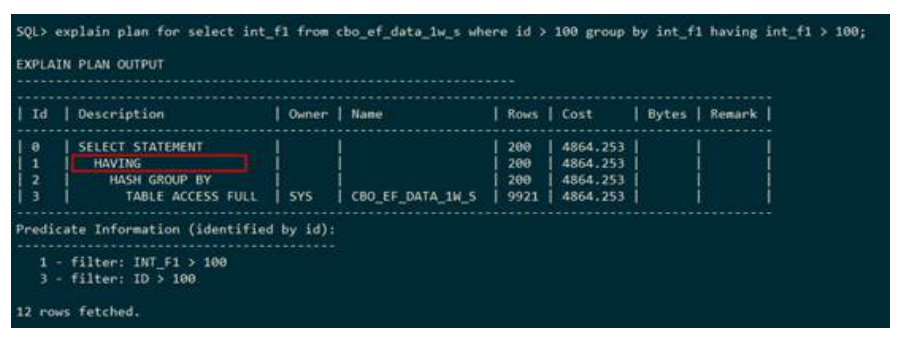
– HAVING(过滤)
上述执行计划表示:通过使用建立hash表的方式进行分组,之后利用having条件过滤结果,并将结果返回到上一层。执行计划中使用HAVING表示分组的过滤。
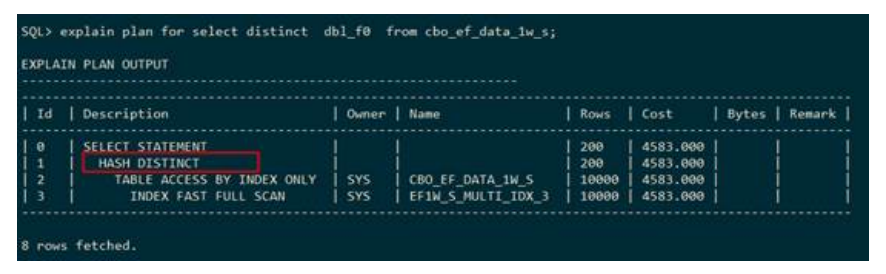
● 去重
– HASH DISTINCT(哈希去重)
上述执行计划表示:通过使用建立hash表的方式进行去重。执行计划使用HASH DISTINCT表示哈希去重。
– INDEX DISTINCT(索引去重)
上述执行计划表示:通过使用索引的方式进行去重。执行计划使用INDEX DISTINCT表示索引去重。
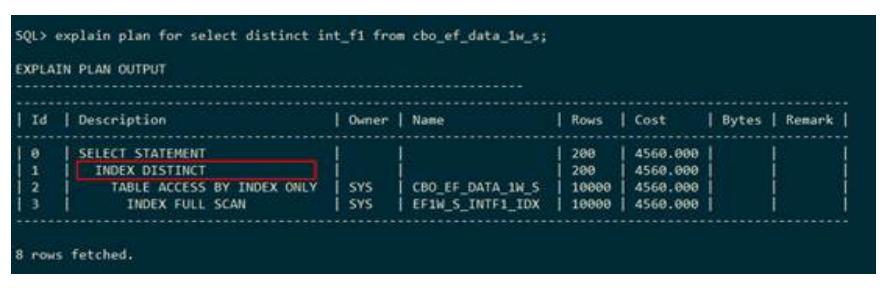
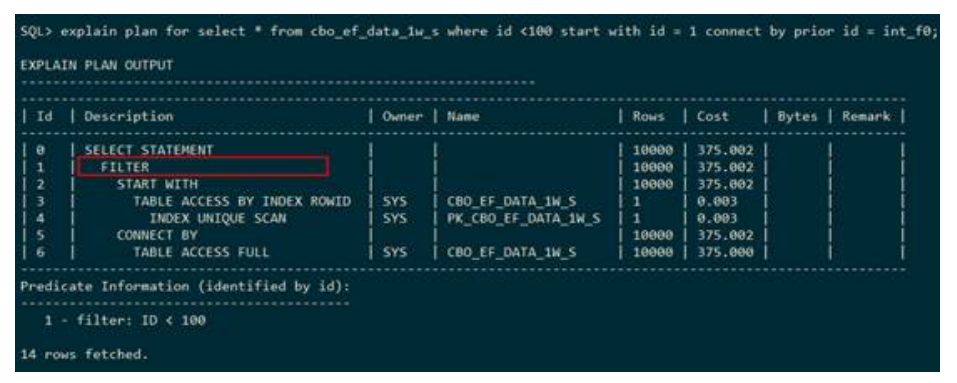
● 层级查询
下列执行计划表示:在层级查询中第一层走表s和表t的嵌套查询,并且表s走索引
pk_cbo_ef_data_1w_s的唯一扫描,表t走索引ef1w_s_intf0_idx的范围扫描;层级查询的其他层走表s和表t的嵌套查询,并且两表走全表扫描。执行计划中使用 START WITH表示第一层,CONNECT BY表示其它层。
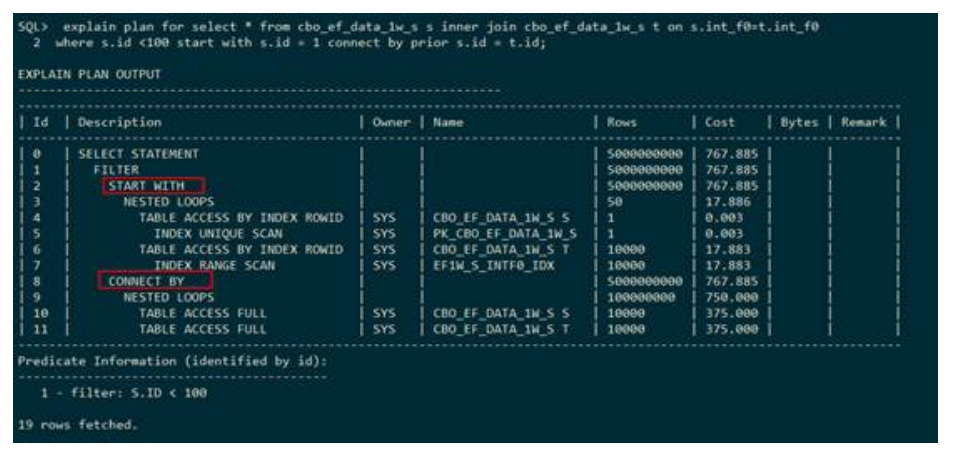
● 排序
– 普通排序(QUERY SORT ORDER BY)
下列SQL语句只需要单纯的排序,执行计划中使用QUERY SORT ORDER BY 表示排序。
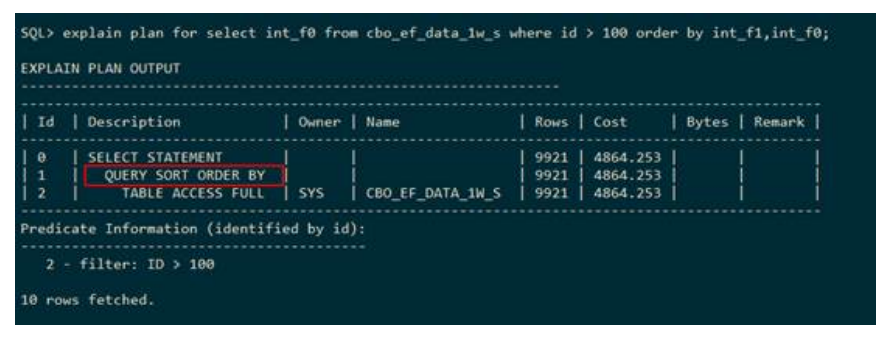
– SORT GROUP BY(分组排序)
下列SQL语句既要排序,也需要要分组,在执行计划中使用SORT GROUP BY 表示既要分组,也要排序。
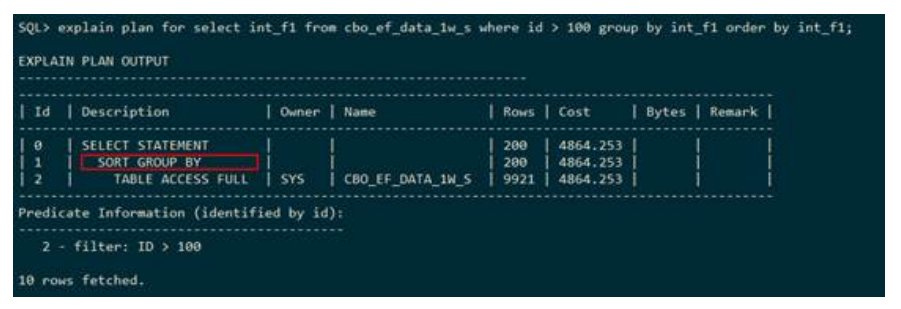
– SORT DISTINCT(排序去重)
下列SQL语句既要排序,还要去重。行计划中使用SORT DISTINCT表示既要排序,还要去重。
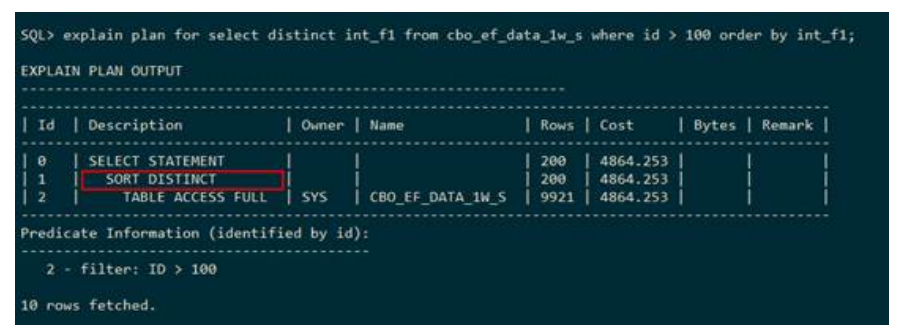
– QUERY SORT SIBLINGS ORDER BY(兄弟节点之间的排序)
下列SQL语句表示对层级查询之后的结果进行兄弟节点之间的排序,必须与 CONNECT BY一起使用。执行计划中使用QUERY SORT SIBLINGS ORDER BY 表示兄弟节点之间的排序。
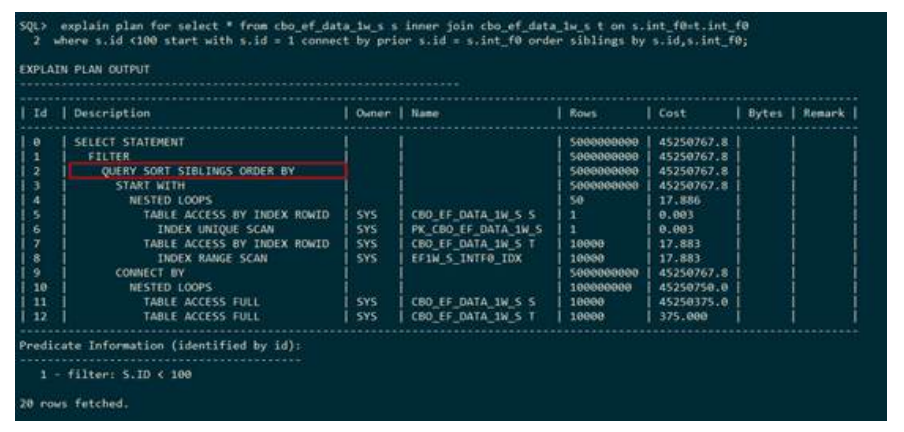
● UNION/UNION ALL
下列执行计划表示:表t1和表t2走索引快速全扫描之后的结果进行union。得到结果后再与t3表进行union all。执行计划中使用UNION ALL表示UNION ALL,使用 HASH UNION表示UNION。
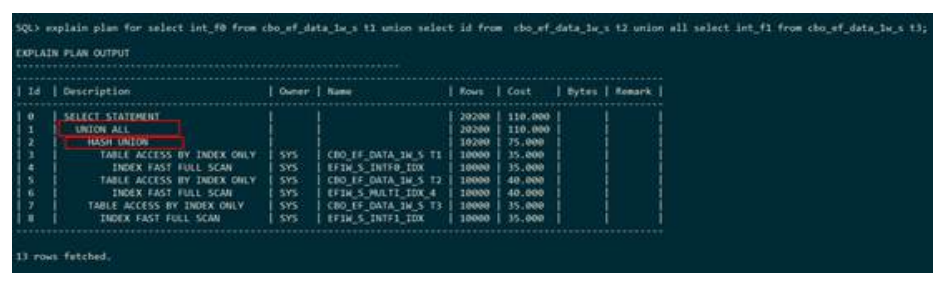
● CONCATENATION(OR扩展)
下列执行计划表示:对表t1和表t2走索引扫描之后的结果进行or扩展。执行计划中使用CONCATENATION表示OR扩展。
● PIVOT/UNPIVOT
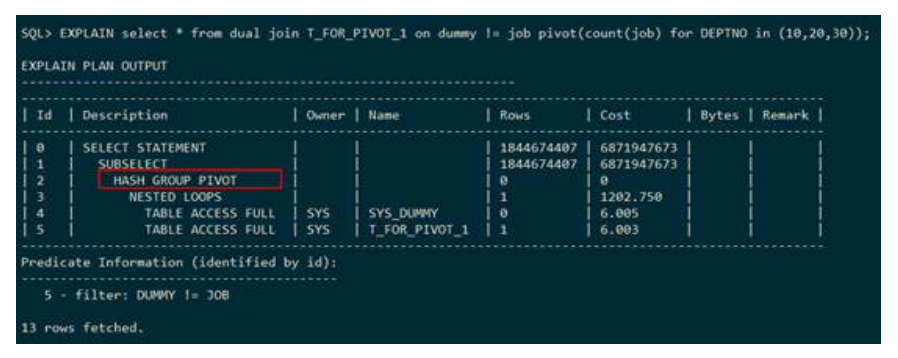
– PIVOT(行转列)
下列执行计划表示:dummy和t_for_pivot_1关联之后的结果进行哈希行转列。执行计划中使用PIVOT表示行转列。
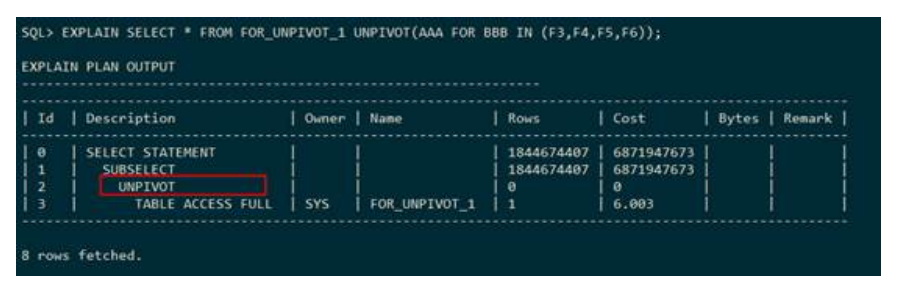
– UNPIVOT(列转行)
下列执行计划表示,表for_unpivot_1的结果进行列转行。执行计划中使用 UNPIVOT表示列转行。
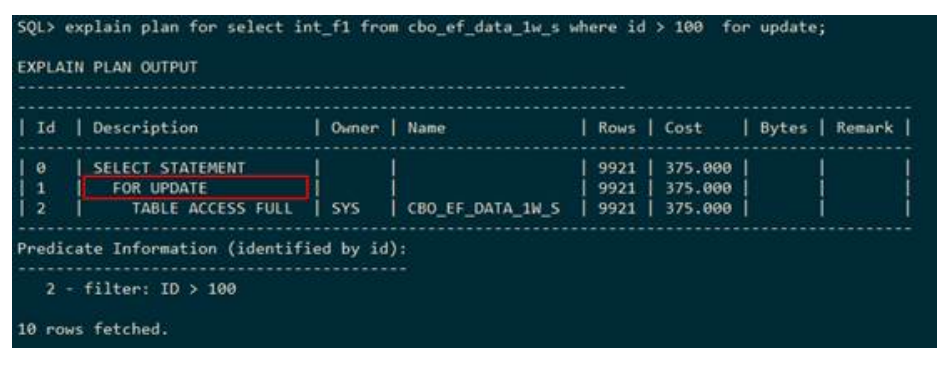
● FOR UPDATE
下列执行计划表示:对于下层即cbo_ef_data_1w_s全表扫描得到的结果进行加锁,并将结果返回到上一层。执行计划中使用FOR UPDATE表示对下层数据进行加锁。
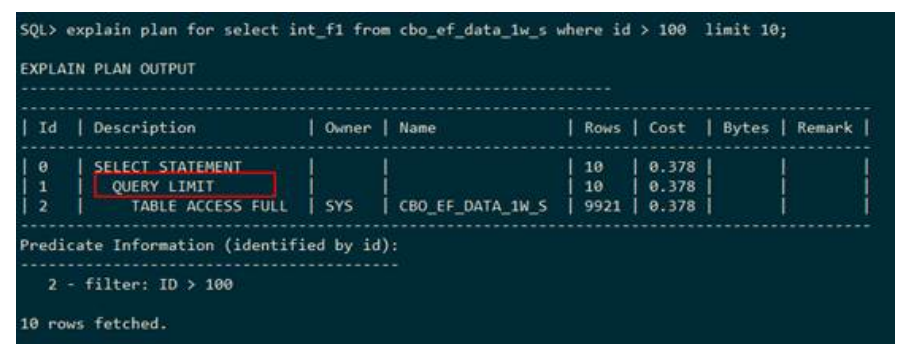
● LIMIT/ROWNUM
– QUERY LIMIT
下列执行计划显示:下层即cbo_ef_data_1w_s全表扫描得到的结果只取前面10条记录。执行计划使用QUERY LIMIT表示限制输出多少条。
– SELECT LIMIT
上述执行计划显示:下层即union all得到的结果只取前面10条记录。执行计划使用SELECT LIMIT表示限制输出多少条。
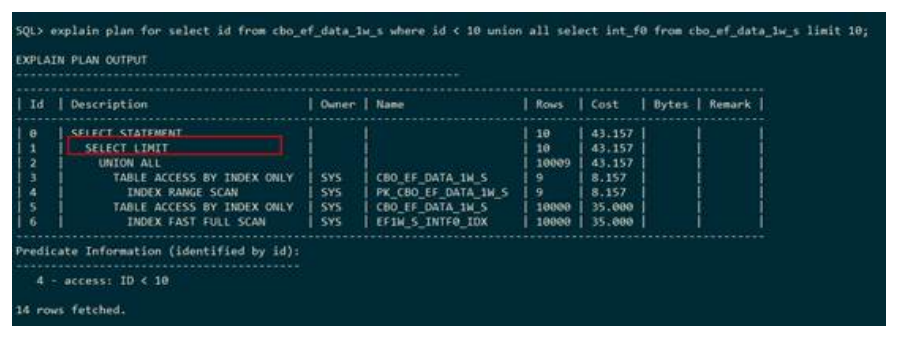
● ROWNUM FILTER
下列执行计划显示:下层即cbo_ef_data_1w_s全表扫描得到的结果,使用id >100过滤数据,并只取满足条件的前9条记录。
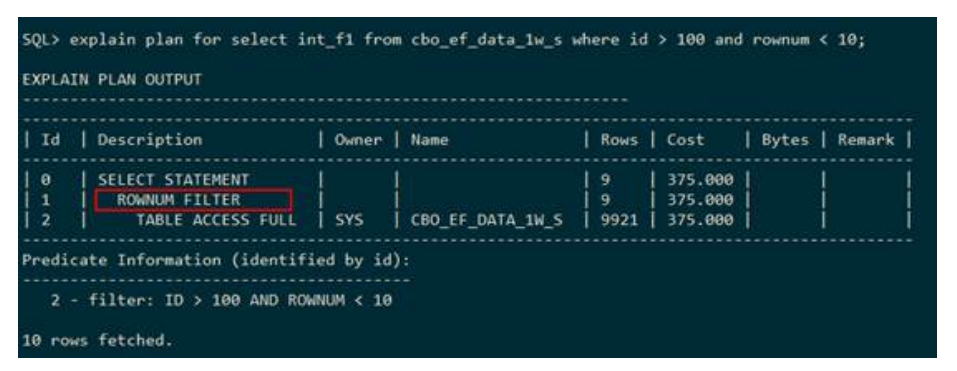
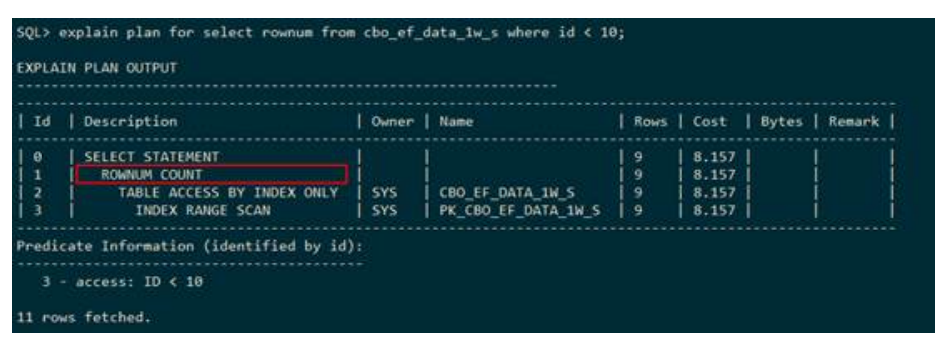
● ROWNUM COUNT
下列执行计划显示:下层即cbo_ef_data_1w_s索引扫描得到的记录数。执行计划使用ROWNUM COUNT记录下层结果集个数。
● WINSORT
下列执行计划显示:对表求max窗口函数的值。执行计划使用WINSORT表示窗口函数。